The Dump Analogy: Forge vs. Function
In my early days scavenging the electronic recycling bins in Rural Wisconsin, I learned that there are two ways to understand a machine: how it was built, and how it runs. Building a high-performance engine requires a massive forge, heavy industrial tools, and thousands of hours of precision engineering. But once that engine is bolted into a chassis, running it only requires a spark and a fuel source. The forge is where the machine is created; the chassis is where it performs its duty.
Artificial Intelligence operates on the exact same principle. The creation of the model—the "forge"—is technically called Training. The act of using that model to generate a response—the "running"—is called Inference. If you want to achieve technical sovereignty, you must understand the "mechanical wall" between these two phases. This isn't just a semantic difference; it is a fundamental hardware and data reality that determines who owns the intelligence you use.
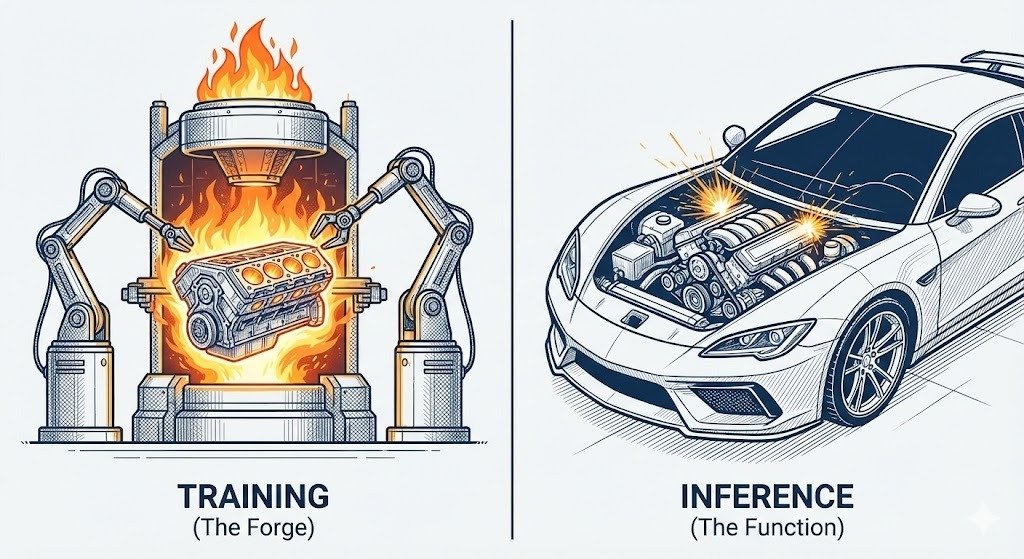
The Forge: What is AI Training?
Training is the most computationally expensive and time-consuming phase of the AI lifecycle. It is the intensive process by which a model learns the statistical patterns, nuances, and relationships of human language. This is where the machine is "forced" to observe billions of examples and adjust its internal variables to accurately represent the input data.
To understand training, you must understand the scale of the fuel. Training data is most commonly measured in Tokens. Modern Large Language Models (LLMs) are fed trillions of tokens worth of data—books, code, scientific papers, and high-quality web text. As the model moves through this ocean of information, it attempts to predict the next word in a sequence.
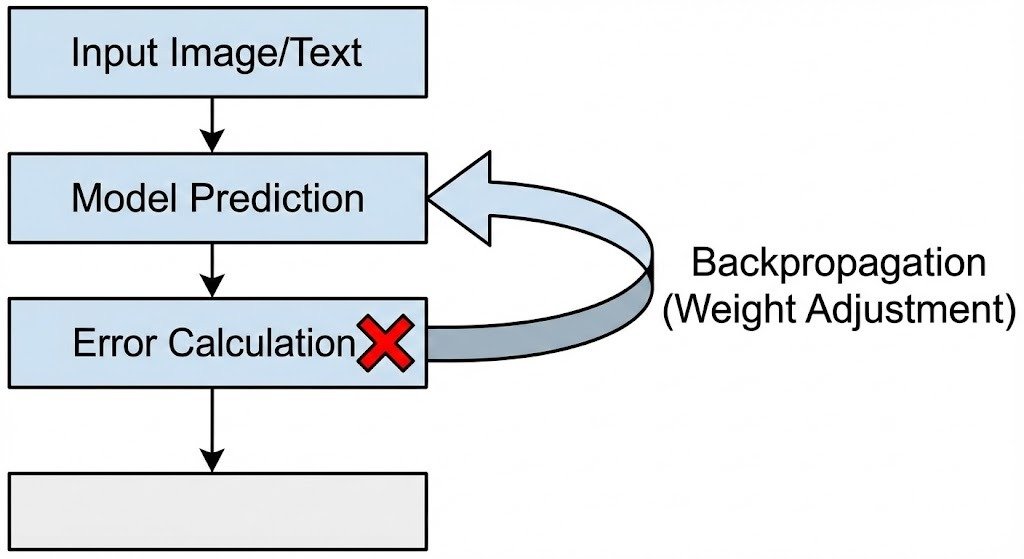
When the model makes an incorrect prediction, a mathematical process called Backpropagation calculates the error and sends it back through the network. This process adjusts the model's Weights. These weights are the numerical values that define the strength of the connections between "neurons" in the digital network. This is the only phase where the model's internal knowledge is fundamentally shaped.
Training requires enormous resources. We aren't talking about a high-end gaming PC; we are talking about massive clusters of thousands of specialized GPUs like the NVIDIA H100. These industrial-scale operations can cost hundreds of millions of dollars and take months of continuous computation. The result of this monumental effort is a single, static file: a Checkpoint. This checkpoint is a snapshot of the binary weights that constitute the model's "intelligence."
The Action: What is AI Inference?
Once the training is finished and the checkpoint is "frozen," we have a usable model. Inference is the technical term for the phase where we actually use that pre-trained model to generate a response to a new prompt. We are no longer teaching the machine; we are asking it to apply the frozen knowledge stored in its weights.
Inference is the "Thinking" phase. When you type a prompt into an interface, the computer performs a massive series of mathematical calculations (matrix multiplications) using the pre-trained weights to predict the most likely next token. Unlike training, which is about optimization, inference is about calculation.
The most significant difference for the end-user is the hardware requirement. Because the model isn't being updated or optimized during this phase, inference requires significantly less power than training. This efficiency allows us to take a model that cost $100 million to train and run it on consumer-grade hardware, such as a laptop with a modern GPU or an Apple Silicon Mac. This is the gateway to Local AI.
The Mechanical Wall: Statelessness
A common misconception—and a major source of AI-related anxiety—is the idea that the AI "learns" from you as you talk to it. In a standard inference session, the model does not learn from your data. The weights that were created during the training forge are static and unchangeable during a normal chat session.
Technically, inference is stateless relative to the base model. While the model can remember what you said within the current conversation (by holding those tokens in its "Context Window"), it does not permanently change its internal weights or "personality" based on your individual prompts. To change the weights, you would need to run a new training or "fine-tuning" pass, which is a different operation entirely.
This is a critical security distinction for business and personal use. When you run Local Inference, you can be certain that your private medical data or legal strategies aren't being "baked" into the model for the next user to see because the inference engine simply doesn't have the "forge" tools attached to it by default.
The Hardware Reality: Cold Starts and VRAM
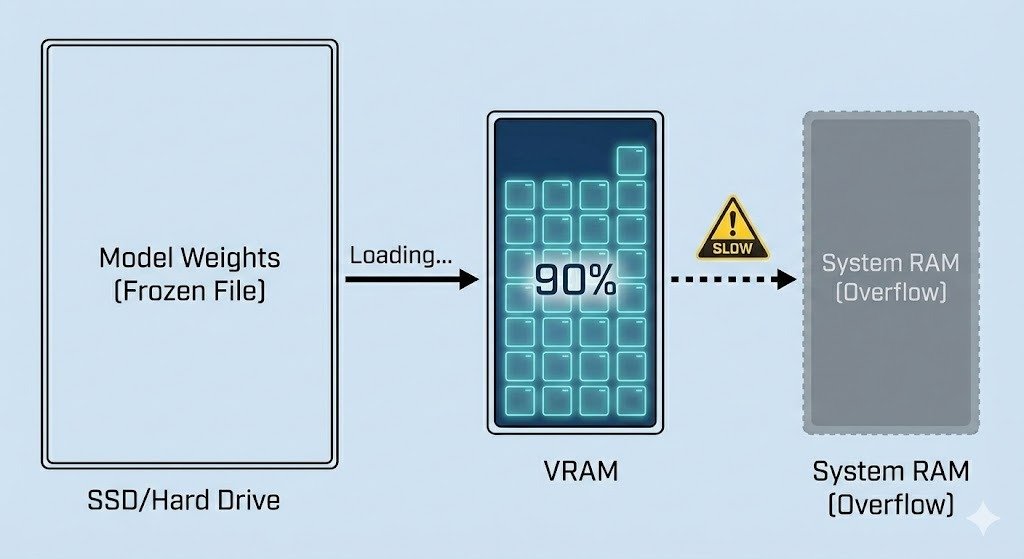
At the dump, if you want a machine to work, you have to get the internal components moving. In AI, this is the "Cold Start" problem. Because inference relies on performing math on the weights, those weights must first be moved from your storage (SSD) into your active memory.
A cold start is the delay when loading a model into RAM or VRAM (Video RAM) before the very first response can be generated. For a large model (like a 70B parameter model), this can take several seconds as gigabytes of data are shuttled onto the GPU. This is why VRAM—the memory dedicated to your graphics card—is the most precious resource in modern computing.
If you don't have enough VRAM to hold the entire weight set, the inference engine may attempt to "offload" parts of the model to your system RAM. This prevents a crash, but it results in a massive performance penalty, often making the AI too slow to be useful. Understanding your VRAM capacity is the price of admission for running local, private intelligence.
Tactical Insight: Why Local Inference?
When you use a cloud-based AI, the inference math is happening on someone else's silicon in a data center you don't control. This means your prompts—your thoughts, your input—are sent across the internet to be processed by a third party. Local Inference is desirable because it provides absolute privacy and eliminates the need to send private data to a training server controlled by a corporation.
Furthermore, local inference removes the dependency on an internet connection. If the grid goes down or a platform decides to censor your "input," your local weights remain ready to serve. Just as I learned to trace the copper veins of logic in the recycling bin at a dump in Rural Wisconsin to see how the machine worked, you are now learning to control the very math that generates the machine's output.
The Logos of Learning
Knowledge and Wisdom are God-given gifts, but the math of their delivery is a matter of stewardship. Training is the creation of the mind; Inference is the exercise of that mind. One is a monument built by corporations using trillions of tokens; the other is a tool that belongs to you through your own hardware.
As we move deeper into the Master Path, we will explore the nuances of Tokens and Context—the specific "fuel" that moves through the inference engine. But for now, hold onto this foundational internal map: Training builds the weights, Inference uses them. One requires a factory; the other requires only a spark.
Steward your compute well. Own the inference. Rule the machine.