The Synapse of the System: Understanding Weights
In my early days scavenging the electronic recycling bins at a dump in Rural Wisconsin, I realized that every machine is a map of influences. On a circuit board, a resistor doesn't just block current; it determines how much "voice" a particular signal has in the final output. If you swap a 1k resistor for a 1M resistor, you haven't just changed a part—you've reshaped the machine's logic.
Large Language Models operate on this exact principle, but at a scale that defies human imagination. Inside a neural network, Weights are the parameters that determine the strength of connection between neurons. If a "Neuron" in the network receives an input, it multiplies that input by a specific weight. Connectivity is everything. If the Weight is high, the signal passes through strongly, influencing the final prediction. If it is low (or zero), the signal is effectively silenced.

When we talk about a model with 70 billion parameters, we are saying the model has 70B weights that determine its behavior. These numbers—often referred to as Neuro Weights—are the "Frozen Brain" that was forged during the Training phase. These weights are not just random numbers; they are the stored record of every pattern, fact, and "vibe" the model learned from its massive training dataset.
The Offset of Logic: The Role of Bias
Weights provide the strength, but life—and logic—rarely starts at zero. In electronics, we often use a "DC Offset" to shift a signal into a range where it can be processed. In neural networks, this is the role of the Bias.
A Bias in this context is a constant value added to the sum of inputs to shift the activation function. If Weights represent the slope of the line (how much things change), the Bias represents the intercept (where the line begins). Biases allow the model to move its "logic" away from the origin, ensuring that a neuron only fires when a specific threshold of evidence is met, regardless of how strong individual inputs might be.
Without Biases, a neural network would be mathematically shackled to the origin, unable to learn complex patterns that don't pass through (0,0). By combining billions of Weights and Biases, the AI creates a high-dimensional landscape of "truth" that can map the nuances of human language.
The Spark: Activation Functions
Once the inputs have been multiplied by the weights and adjusted by the biases, the model has to decide: "Does this signal matter?" This decision is handled by the Activation Function.
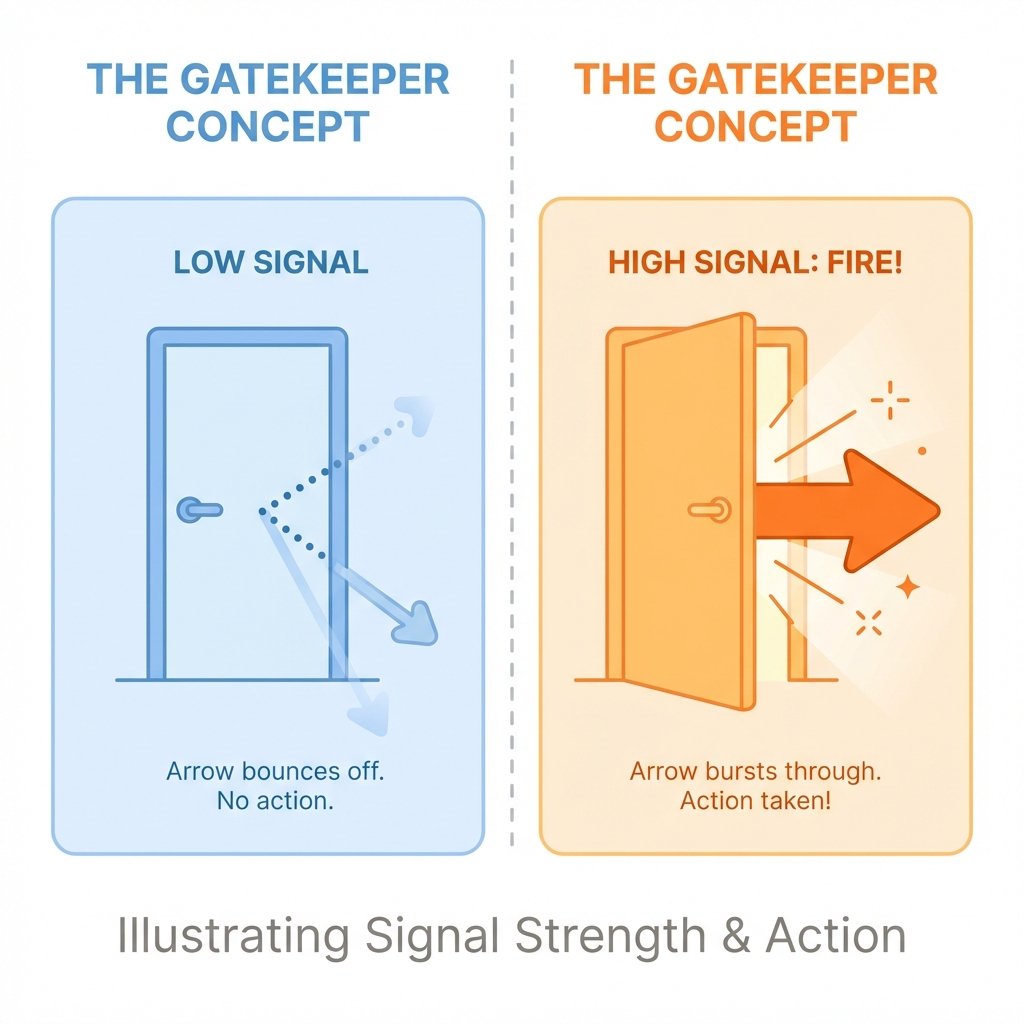
An Activation Function is a mathematical filter that decides whether a neuron should "fire" based on its weighted input. Common functions like ReLU (Rectified Linear Unit) or Sigmoid introduce non-linearity into the system. This non-linearity is critical; without it, even a model with 100 trillion parameters would be no more intelligent than a simple linear equation. The activation function is the "spark" that allows the machine to perform complex reasoning.
The Forge: How Weights Are Created
How do we know which of those 70 billion numbers should be 0.45 and which should be -0.12? This is the process of training. When a model is first initialized, it uses Random Initialization. This is used to ensure neurons start with different values and learn different features, a concept known as "symmetry breaking." If every neuron started with the same number, they would all learn the same thing, and the model would be useless.
The model then goes through millions of iterations of guessing. It reads a sentence, predicts the next word, and compares its guess to the actual text. The difference between the guess and the truth is the "Error" (or Loss). To fix this error, the model uses two critical tools: Backpropagation and Gradient Descent.
Weights are updated during training via Backpropagation and Gradient Descent. Backpropagation calculates exactly how much each weight contributed to the error, and Gradient Descent determines the "step" required to fix it. The size of this step is controlled by the Learning Rate. The Learning Rate determines the step size used when updating weights during training. If it's too high, the model "jumps" over the solution and fails to learn; if it's too low, the training takes forever and stalls.
The Danger Zone: Overfitting
In the recycling bins of Rural Wisconsin, you sometimes find a part that looks perfect but only fits one specific, obscure brand of 1994 VCR. It lacks utility because it's too specific. In AI, this is called Overfitting.
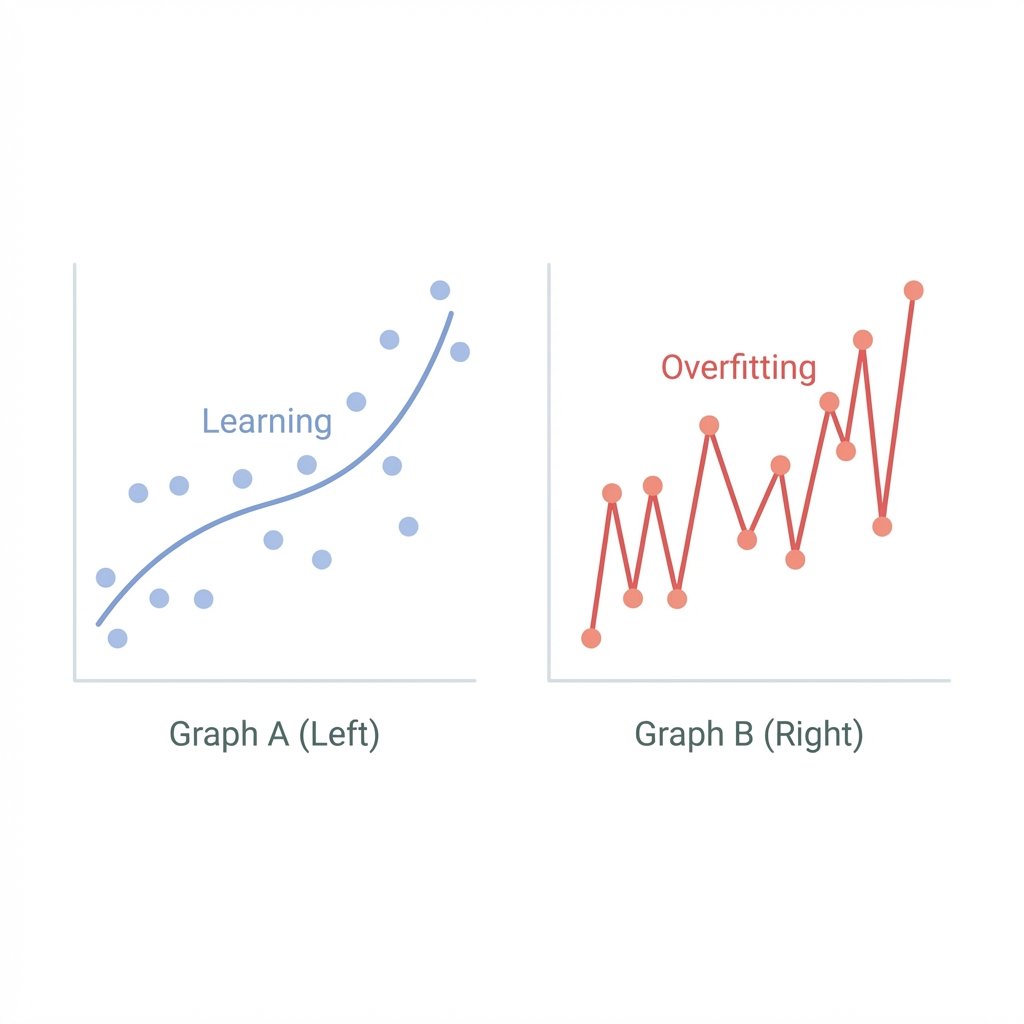
Overfitting occurs when a model learns training data too well but fails on new data. The model effectively memorizes the exam questions instead of learning the underlying subject. It mistake "noise" in the training data for actual patterns. A well-trained model must achieve "Generalization"—the ability to apply its learned weights to scenarios it has never seen before. This is the hallmark of true intelligence.
Sovereign Refinement: Fine-Tuning
Even after the massive "pre-training" forge is finished, we can still perform Fine-Tuning. This process slightly adjusts the pre-trained weights to fit new data patterns. For example, you might take a model trained on the entire internet and "fine-tune" it on medical journals or legal case law. You aren't rebuilding the brain; you are "calibrating" it for a specific job.
This is the final step in Logic Sovereignty. By running local models with tools like Ollama, you can apply your own fine-tuned weights, ensuring the AI's "values" and "biases" align with your own, rather than those of a distant corporation.
Stewardship of the Frozen Logic
The Weights and Biases of a model are its soul. They are the mathematical manifestation of everything it has "witnessed" during its creation. We are the stewards of these numbers. When we prompt a model, we are asking a specific configuration of 70 billion values to process our thoughts.
Understanding these parameters gives you the power to see through the "Magic" of AI. It isn't a ghost in the machine; it is a mathematical architecture. By mastering the concepts of Tokenization, Context, and now Weights, you have completed the foundational pillar of the Master Path.
You no longer see a chat box; you see the Logic Veins. You see the weights shifting, the biases offsetting, and the activations firing. You are now ready to move from understanding the machine to Commanding the machine.