The Scrapyard Revelation
Before I understood code, I understood discarded silicon. Growing up in Minnesota and spending my formative years scavenging the electronic recycling bins at the local garbage dump in Rural Wisconsin, I learned a fundamental truth: every machine, no matter how complex, is a collection of parts following a script. I would pull apart old motherboards, tracing the copper veins of logic, trying to see the "ghost" in the machine.
As I moved into the world of Artificial Intelligence, I realized that many people view Large Language Models (LLMs) as mystical, sentient entities—digital spirits trapped in silicon. They aren't. An LLM is a machine. It is a massive statistical engine designed for one specific, singular task: predicting the next likely word in a sequence. It is not magic; it is math.
Defining the Machine: What is an LLM?
When we say LLM (Large Language Model), we are describing three specific characteristics. First, it is "Large"—not just in file size (which can reach terabytes), but in the sheer scale of the historical data it has ingested and the billions of internal connections it maintains. Second, it is "Language"-focused, meaning its primary medium of exchange is human-readable text. Third, it is a "Model," a mathematical representation of how language works, captured in a steady state.
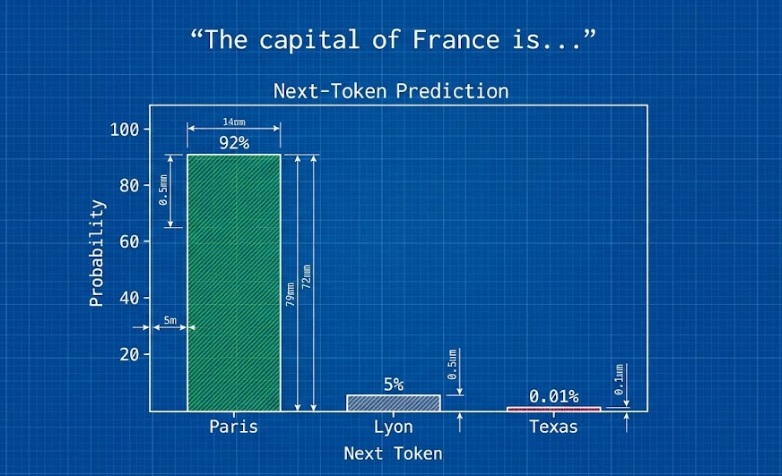
It is crucial to understand that an LLM is not aware of its output. It does not "know" things in the way you do. It does not have beliefs, feelings, or a consciousness. Instead, it functions as a Next-Token Prediction Engine. When you ask it a question, it looks at the string of text provided (the prompt) and calculates the probability of what the next word should be based on everything it has ever read. It repeats this process thousands of times per second until a full response is formed.
The Mechanical Heart: Symbols and Probability
At its core, an LLM views text as numbers. It doesn't see "Apple"; it sees a coordinate in a multi-dimensional space. This process is called Tokenization. The model breaks your text into small chunks—tokens—and assigns each a numeric ID.
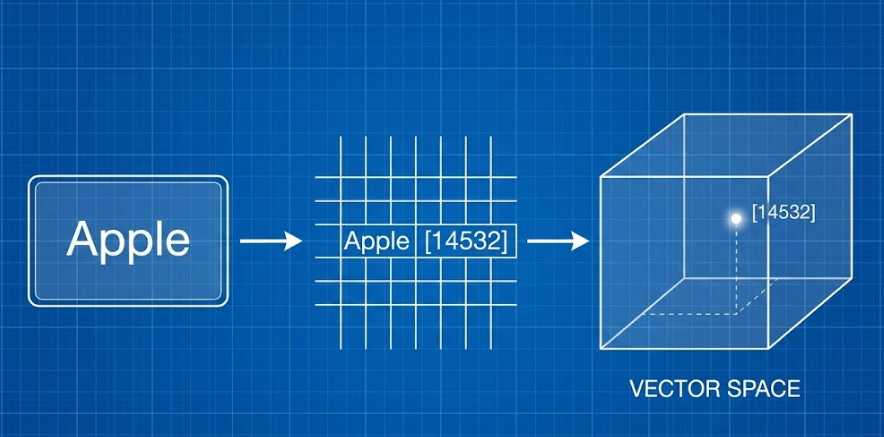
Inside the model's structure are trillions of Parameters. Think of these as the "knobs" on a massive radio. During its training phase, the model adjusted these billions of variables (or "internal weights") to minimize the error in its predictions. These parameters are what define the model's behavior and personality. A model with 70 billion parameters has a much more complex "map" of language than one with 7 billion, allowing for more nuanced and sophisticated output.
The History of the Breakthrough
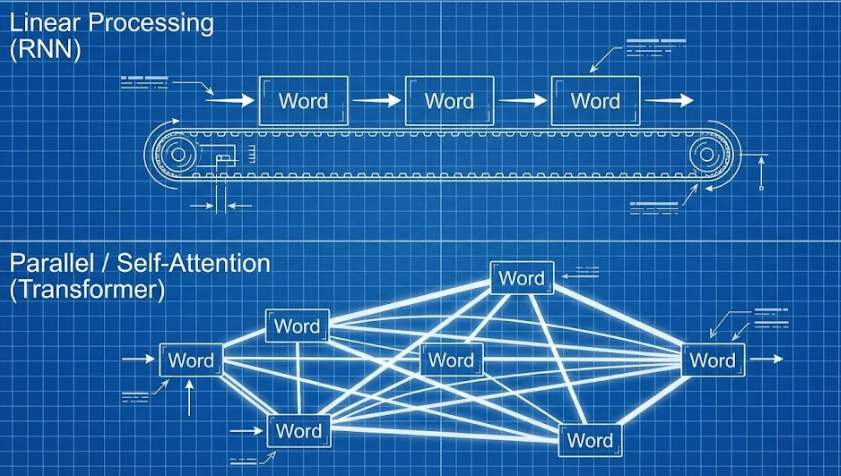
The AI world was stagnant for decades, stuck in "Neural Networks" that forgot the beginning of a sentence by the time they reached the end. The revolution happened in 2017 when a team of Google researchers published a paper titled "Attention Is All You Need."
This paper introduced the Transformer architecture, which is the foundation of every modern LLM we use today, from ChatGPT to Claude. The breakthrough was the "Self-Attention" mechanism. Before Transformers, AI processed text linearly (one word at a time). Transformers process everything at once, allowing the model to pay "Attention" to the relationship between words no matter how far apart they are in a document. This is why a model can remember the context of a protagonist's name 10,000 words later.
This architecture gave birth to the GPT series of models. GPT stands for Generative Pre-trained Transformer. "Generative" because it creates new text; "Pre-trained" because it has already finished its core education; and "Transformer" because of the 2017 Google breakthrough that made it all possible.
The Library of Babel: Training Data
Where does the knowledge come from? An LLM's "world model" is built during the Pre-training phase. In this stage, the model is fed massive datasets of text from the internet, digitized books, scientific papers, and computer code.
During pre-training, the model isn't trying to learn "facts." It is learning general patterns. It observes that the word "Paris" is often followed by the word "France," and that "2 + 2" is almost always followed by "4." It builds a statistical map of human thought. This is why LLMs can sometimes confidently state incorrect information (hallucinations); they are prioritizing the probability of a word pattern over the truth of a factual claim. They are reflecting the collective output of humanity, including our biases and our brilliance.
Tactical Insight: Pre-training vs. Inference
It is helpful to think of the AI lifecycle in two distinct chapters.
Chapter 1: Pre-training
This is the expensive, months-long process where the model reads the internet. It establishes the "General Patterns" and foundational knowledge. Once pre-training is finished, the model file is "frozen."
Chapter 2: Inference
This is what happens when you type a prompt. The model isn't learning anymore; it is "calculating" or "using" its pre-trained patterns to generate a response. This is the Inference phase.
Prompting: The Steering Wheel
If the LLM is a massive engine, Prompting is the steering wheel. A prompt does not change the underlying model, but it sets the context and constraints for the output. You are essentially telling the model which part of its massive statistical map to focus on.
A good prompt narrows the probability field. Without a prompt, the model could calculate that any word in the dictionary is a possible next token. By providing a prompt like "Explain this like a quantum physicist," you are shifting the weights so that technical, precise tokens become far more probable than casual ones. You are navigating the latent space of the machine.
The Stewardship of the Logic
As a follower of Jesus Christ, I believe that Knowledge and Wisdom are gifts, but they require stewardship. An LLM is a "Stochastic Parrot"—a term used by researchers to describe a system that repeats patterns without true understanding. It is a mirror, not a source.
Understanding the math (the "Logos") of the machine is the first step toward sovereignty. When you realize that the AI is just a file—a collection of weights and biases—you lose the fear of it. You stop seeing it as a threatening "Other" and start seeing it as a tool that can be mastered, critiqued, and local-hosted for the benefit of your family, your business, and your faith.
Don't let the marketing hype cloud your judgment. Understand the Input to Master the Output. Own the weights. Rule the machine.