The Law of the Dump: Context as Currency
When I moved to Rural Wisconsin in 2000, I spent my afternoons kneeling in electronic recycling bins at a dump, salvaging components from PCs that had been written off as junk. To the untrained eye, it was just a pile of scrap. To me, it was a logic puzzle. I learned quickly that the most powerful processor in the world is useless if it doesn't have the right data at the right time. This is the foundational law of Inference: the machine is only as capable as the context it currently holds in its active memory.
In the realm of Large Language Models (LLMs), we call this active memory the Context Window. Measured in tokens, this window is the "attention span" of the model. Context Engineering is the practice of selectively feeding information into the prompt to maximize the relevant information provided to the model within its token limit. It is not about simply giving the AI more words; it is about Density and Relevance.
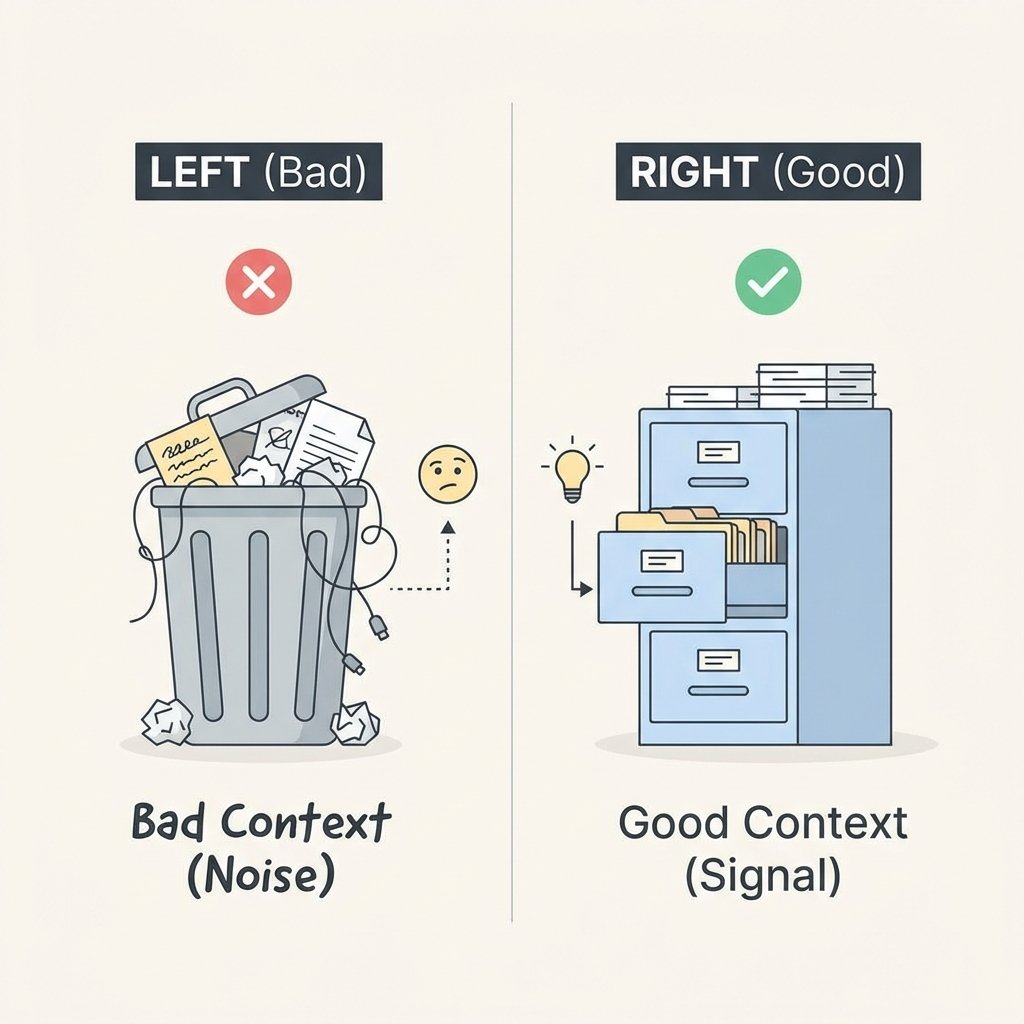
If you treat the context window like an infinite bucket, you'll end up with "Garbage Out." But if you treat it like Strategic Real Estate, you transform the AI into a high-precision tool. Every token you use is a trade-off between clarity and cost. Mastering this trade-off is what separates a casual user from an AI Systems Architect.
The Physics of the Window: Long-Context vs. High-Density
We are living in an era of massive context windows. Models like Gemini 1.5 Pro offer windows exceeding two million tokens. This Long-Context capability is a game-changer because it helps with large codebase analysis and complex legal document review. You can drop an entire repository or a 500-page contract into the window and ask the model to find a single flaw in the logic.
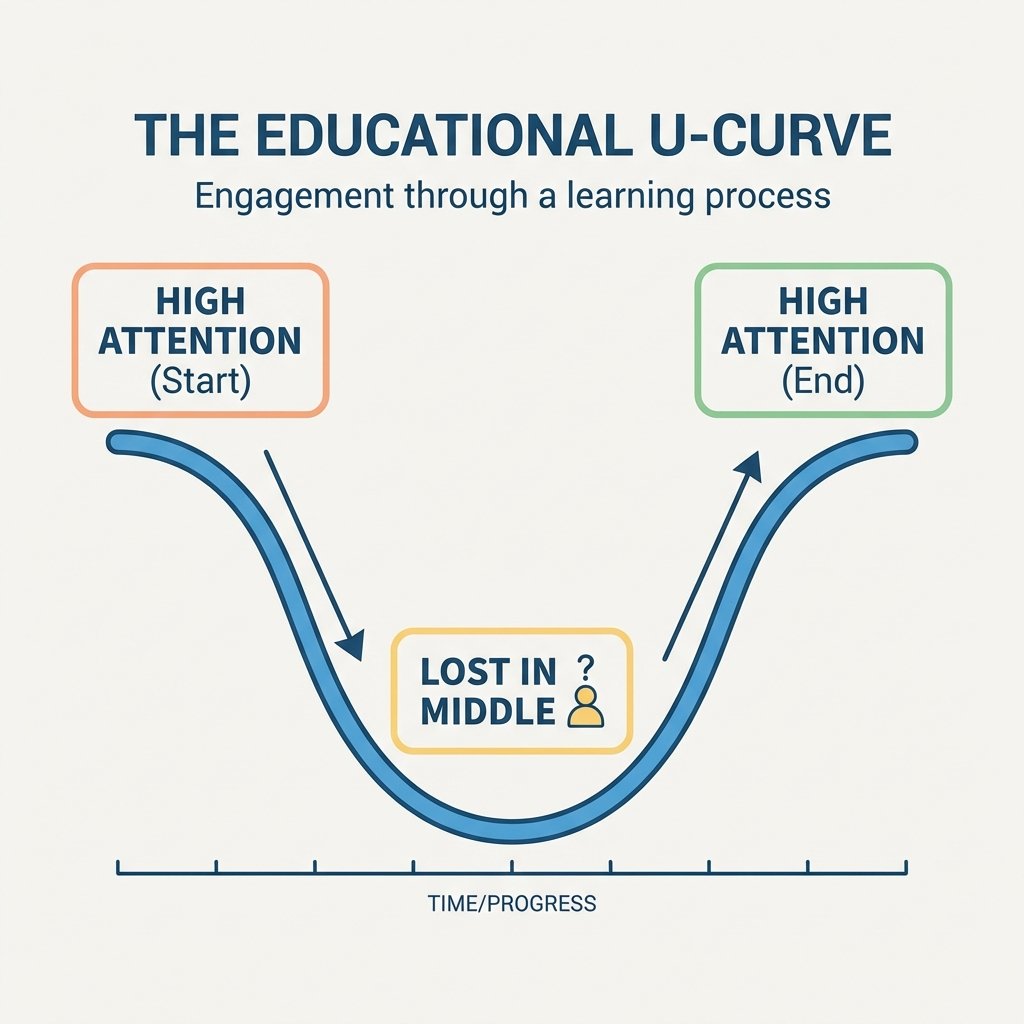
However, more space doesn't always mean better reasoning. A phenomenon known as Lost in the Middle describes the tendency for models to ignore information in the middle of long prompts. Research shows that information at the beginning and end of a prompt usually has more weight in the model's self-attention mechanism.
Retrieval Augmented Generation (RAG): The Sovereign Knowledge Hub
What if the information the model needs isn't in its training data? What if you need the model to reference your own private server logs or medical patient data? You don't retrain the model. Instead, you use Context Injection. This is the process of adding external data (like documents or web search results) into the active prompt.
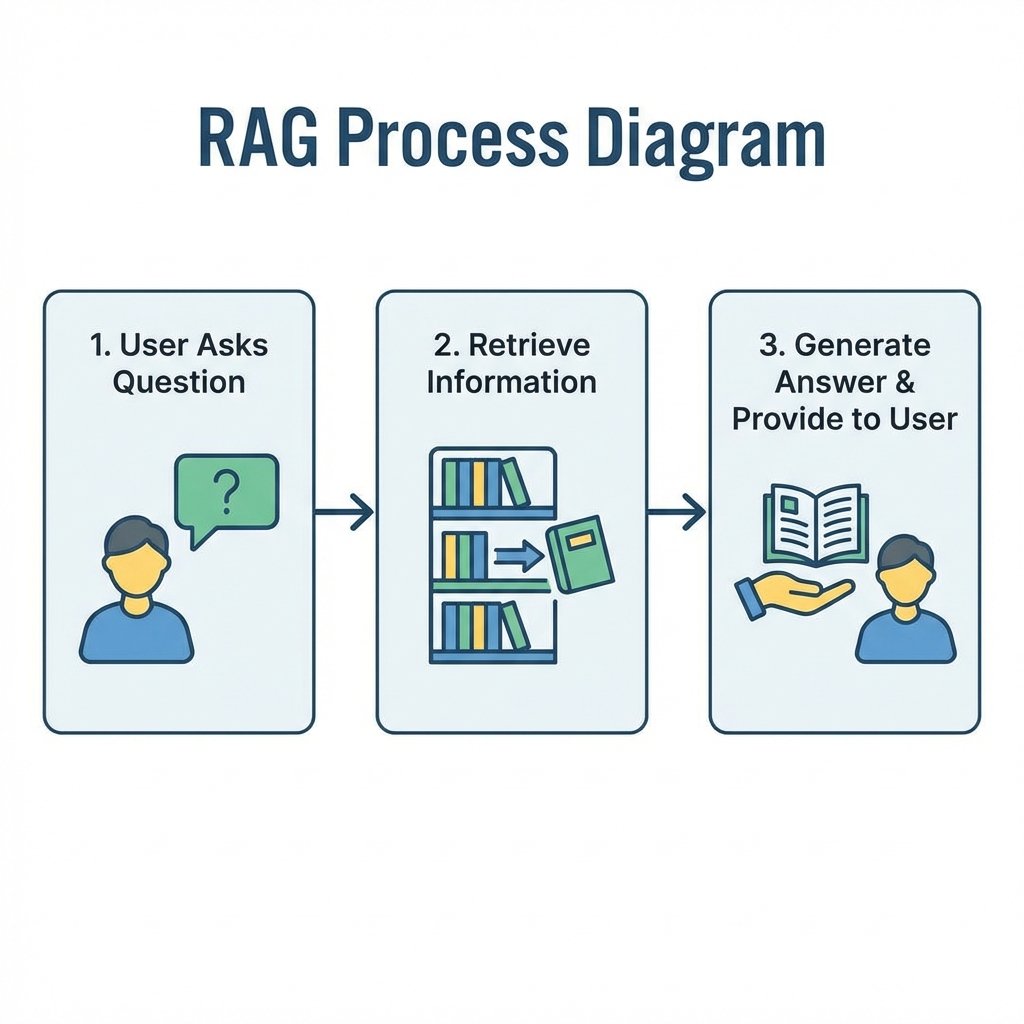
The industry standard for this is Retrieval Augmented Generation (RAG). RAG is the process of searching a database for relevant info and adding it to the prompt before the inference phase begins. This allows the model to be grounded in facts it wasn't originally trained on. A typical RAG system consists of a Knowledge Base, which is usually a collection of indexed documents like PDFs, text, or research papers that the AI can "glance at" for every query.
Vectors and Semantic Search: Beyond the Keyword
In a RAG system, how does the machine find the right document? It doesn't use simple keyword matching. It uses Semantic Search. This is searching for the 'Idea' or 'Intent' behind words rather than just characters. If you search for "liquid," a keyword search might miss "water," but a semantic search will find it because they are conceptually related.
This is possible because every piece of text in a knowledge base is converted into a Vector. In the context of RAG, a 'Vector' is a mathematical representation of a text's meaning within a high-dimensional space. These vectors allow the system to calculate the "distance" between your query and your data. The closer the vectors, the more relevant the information.
By managing these Semantic Vectors, you ensure that the model is only "looking" at the most statistically relevant data. My gift from God—that pattern recognition I discovered at thirteen—has always been a form of manual vector mapping. I could see how the power supply related to the motherboard by their shared logic, not just their labels. RAG does exactly this for human language.
The Hierarchy of Injection: Pruning and Preservation
As an engineer, you must be a steward of the token window. One of the most effective techniques is Pruning. This is the act of removing redundant or irrelevant information from your project files before feeding them to the AI. If you are uploading a codebase, you don't include the dependencies or the compiled binaries. You only include the Source Intent.
Another pillar is Hierarchical Summarization. For massive projects, you don't feed the entire context at once. You summarize sub-modules and pass the "master architecture" first. This gives the AI the high-level map it needs before it dives into the specific code blocks. It preserves the State of the project without overwhelming the model's Attention Budget.
This involves knowing when to inject data from Hugging Face Datasets for broad knowledge grounding or when to rely on your own Indexed Knowledge Base for proprietary facts. The goal is Density: making sure every token moving through the Neuro Weights of the model is doing work.
Practical Stewardship: Slating and Blueprinting
I advocate for a "Clean Slate" approach to context management. Once a task is completed—for example, once we have refined the links on this site—I start a fresh thread. I don't drag the entire history of our conversation into the next task. I carry over only the Site Blueprint and the current Operational Persona defined in the System Prompt.
This keeps the model's internal Transformers focused. If you leave a window open too long, the "drift" becomes inevitable. The model starts following patterns from three hours ago that are no longer relevant to your current problem. By engineering the context slates, you maintain the highest possible level of reasoning across every session.
Summary: Connecting the Digital Lines
Context Engineering is the bridge between raw compute and realized intelligence. It is the realization that a Large Context Window is a tool to be managed, not a convenience to be abused. Whether you are building RAG systems with Semantic Search or simply managing a complex coding thread, you are a manager of attention.
Remember the laws: Context Injection grounds the model in facts. Vector math enables semantic relevance. Lost in the Middle dictates where you put your keys. And Real-time RAG updates outperform fine-tuning for factual accuracy every single time.
By the grace of God, we have been given these systems that can absorb and synthesize human knowledge at light speed. Our job is to provide the Intent. Use your tokens wisely. Architect your context with the same care I used to salvaging those scrap parts in electronic recycling bins at a dump in 2000. When the lines are connected correctly, the machine doesn't just respond—it understands.